

Tiny YOLOv3 CPU-only real-time object detection using a camera; offline detection, script-triggered on-changes or on-demand results with class/scores.
How to add the Darknet YOLO (Obj Detection) robot skill
- Load the most recent release of ARC (Get ARC).
- Press the Project tab from the top menu bar in ARC.
- Press Add Robot Skill from the button ribbon bar in ARC.
- Choose the Camera category tab.
- Press the Darknet YOLO (Obj Detection) icon to add the robot skill to your project.
Don't have a robot yet?
Follow the Getting Started Guide to build a robot and use the Darknet YOLO (Obj Detection) robot skill.
How to use the Darknet YOLO (Obj Detection) robot skill
You only look once (YOLO) is a state-of-the-art, real-time object detection system. using Tiny YOLOv3 a very small model as well for constrained environments (CPU Only, NO GPU)
Darket YOLO website: https://pjreddie.com/darknet/yolo/
Requirements: You only need a camera control, the detection is done offline (no cloud services).
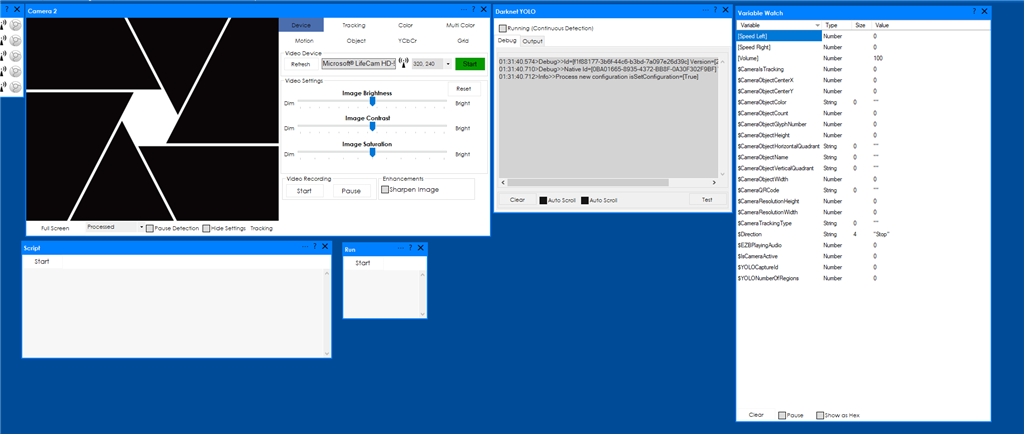
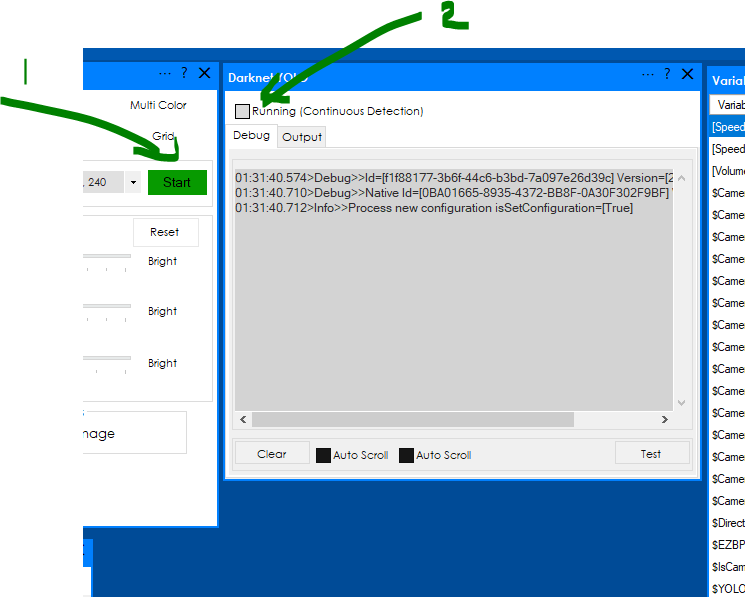
- start the camera.
- check the Running (check box)
The detection will run continuously when the detection results change an On Changes script is executed (check the configuration area):

- Press config
- Edit the on changes script
- on changes Javascript script
you can run the detection on demand, javascript:
controlCommand("Darknet YOLO", "Run");
The above command runs the configured on demand script.
An example of script:
var numberOfRegions=getVar('$YOLONumberOfRegions');
if (numberOfRegions==0)
{
Audio.sayWait('No regions found');
}
else
{
Audio.sayWait('Found ' + numberOfRegions + ' regions');
var classes = getVar('$YOLOClasses');
var scores = getVar('$YOLOScores');
for(var ix=0; ix {
Audio.sayWait('Found ' + classes[ix] + ' with score: ' + (classes[ix]*100) + '%');
}
}


There is a file size limit for plugin uploads. There is a missing file required to operate the plugin.
Please download the following file:
And copy to the plugin folder:
Expected plugin folder content:
hi ptp,
Intriguing item and website.
I have a https://pixycam.com/
EzAng
What's the file size of your entire plugin package? including the .weights file?
And - this is amazing
DJ: 35.5 Mb
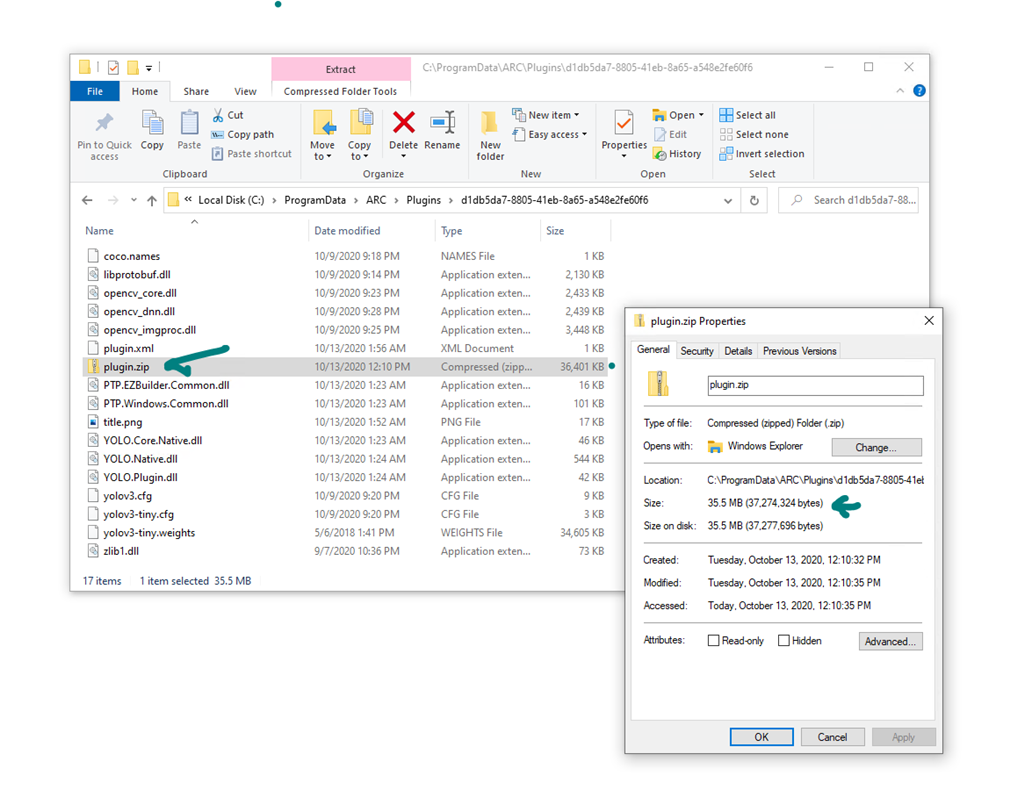
Thanks DJ!Okay great - I'll have amin update the file size on the website for ya
Pedro, this is awsome. Love to see a video of the plug in running. How does it compare in speed to the GPU version shown on their site (Pascal Titan X )?
@Ezang:
indeed a strange/dark name "Darknet" for an AI framework, there are also nightmares: https://pjreddie.com/darknet/nightmare/ it's analogue to google deepdream project, so they played with the words dream... nightmare. The PixyCam is useful to pair with underpowered microcontroller e.g. arduino 8 bits. If you are using ARC the camera control has many more features plus you have additional CPU power.@Fxrtst:
I will do it soon, the plugin requires additional TLCit's important to explain what the plugin does.
Frameworks: Darknet is an open source neural network framework written in C and CUDA similar to TensorFlow, Caffe although is mainly used for Object Detection, and have a different architecture. The frameworks have both the training and inference processes. You can run both without CUDA (CPU only) but be prepared for a huge difference.
Datasets: To train a neural framework you need input (data) e.g. images, sounds, etc. This plugin ships with the following dataset: https://cocodataset.org/ the biggest publicly available. Each dataset requires additional metadata: labels, categories and image optimization (resize image filters) so is not an easy task to create one. Each dataset contains specific categories e.g. people, birds, dogs the COCO has 90 categories, usually other datasets have less than 30.
Model: So the model is the output of a dataset training. The models are not interchangeable between the frameworks. You ll find COCO model for Tensorflow, YOLO etc. Training takes time, huge time if you don't have the GPU power, although the models are framework specific you can convert between them (there are some issues and requirements and sometimes additional scripting) for Yolo there is a tool called DarkFlow (everything is dark ).
).
So the Yolo detection + coco model (245Mb) takes almost 50 seconds (first time) to detect an image on a Intel NUC i7 (my machine) without a CUDA card with 8 GB you can't expect to have FPS only FPM (frames per minute).
I plan to test the AtomicPI (similar to LattePanda) what can you expect with atom processor ? We will see, everyone agrees the game changer is the GPU and only NVDIA has the stuff!
To alleviate the frustration the yolo guys trained the model for a tiny version plus a different configuration/parameters, so with a tiny version you can get some FPS, but, once again the GPU blows the CPU performance.
Tensorflow also released a different engine (Tensorflow Lite) plus TF lite models, that allows you to run lite models in micro-controllers, embedded computers (PI), mobile phones and regular CPUs.
To summarize: The plugin ships with the tiny COCO model (35Mb). Later I'll add the possibility to download the full model (250GB) more accurate but very slow. The plugin was built without CUDA support, so does not matter if you have a CUDA GPU.
Let's hope it can be useful running on a Latte panda.
I found a bug: while running in the continuous mode, I don't stop the detection process, so while the On Changes script is running (Text To Speech say results9, the detection is queueing results.