

Azure TTS for ARC robots: generate natural, customizable neural voices for companion, educational, assistive, and entertainment applications.
How to add the Azure Text To Speech robot skill
- Load the most recent release of ARC (Get ARC).
- Press the Project tab from the top menu bar in ARC.
- Press Add Robot Skill from the button ribbon bar in ARC.
- Choose the Audio category tab.
- Press the Azure Text To Speech icon to add the robot skill to your project.
Don't have a robot yet?
Follow the Getting Started Guide to build a robot and use the Azure Text To Speech robot skill.
How to use the Azure Text To Speech robot skill
The Synthiam ARC robot skill for Azure Text-to-Speech is a powerful integration that enables your robot to generate human-like speech using Microsoft's Azure Text-to-Speech service. This skill allows you to elevate your robotics project to the next level by equipping your robot with a natural and dynamic voice. Whether you are building a companion robot, educational tool, or any other robotic application, this skill enhances user interaction and engagement through spoken language.
Applications
Human-Robot Interaction: Enable your robot to engage in natural conversations with users, making it a more relatable and interactive companion. Educational Tools: Enhance the educational value of your robot by enabling it to provide spoken explanations and instructions to learners. Assistive Technology: Create robots to assist individuals with disabilities by providing spoken assistance and information. Entertainment and Storytelling: Develop storytelling robots to bring characters and narratives to life through speech synthesis.Get started with the Synthiam ARC robot skill for Azure Text-to-Speech and bring your robotic project to life with expressive, human-like speech capabilities. Elevate the user experience, foster engagement, and unlock a world of possibilities with this innovative integration.
Main Window
Configuration Window
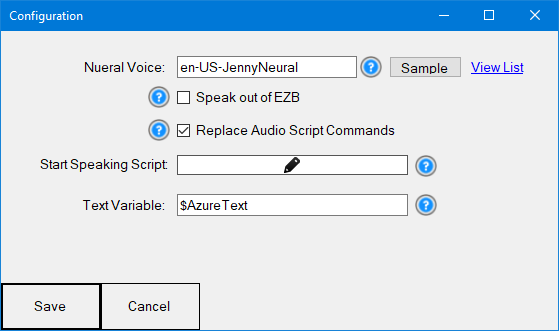
Neural Voice Enter the neural voice that you wish to use. This value can also be dynamically changed using the ControlCommand syntax.
Sample Press the SAMPLE button to hear the sample of the selected voice.
View List View a list of the available voices.
Speak out of EZB If checked, the spoken audio is sent out to the EZB speaker (if supported). Otherwise, the audio is spoken from the PC's default output device.
Replace Audio Script Commands Checking this option will replace the Audio.say() with all other script speak commands with this robot skill. This means you can use this robot skill with traditional Audio scripting commands rather than needing to send the ControlCommand to it. Traditionally, you send a ControlCommand to a robot skill to instruct it to act. When this is enabled, it will override the Audio.say and Audio.sayEZB, etc, commands, and the speech will be spoken from this robot skill rather than the default built-in TTS voice.
Start Speaking Script The script will execute when the text begins to speak.
Speak Text Variable The variable that will hold the text that is being spoken.
Text Variable The variable that stores the current text that is being spoken.
Available Voices
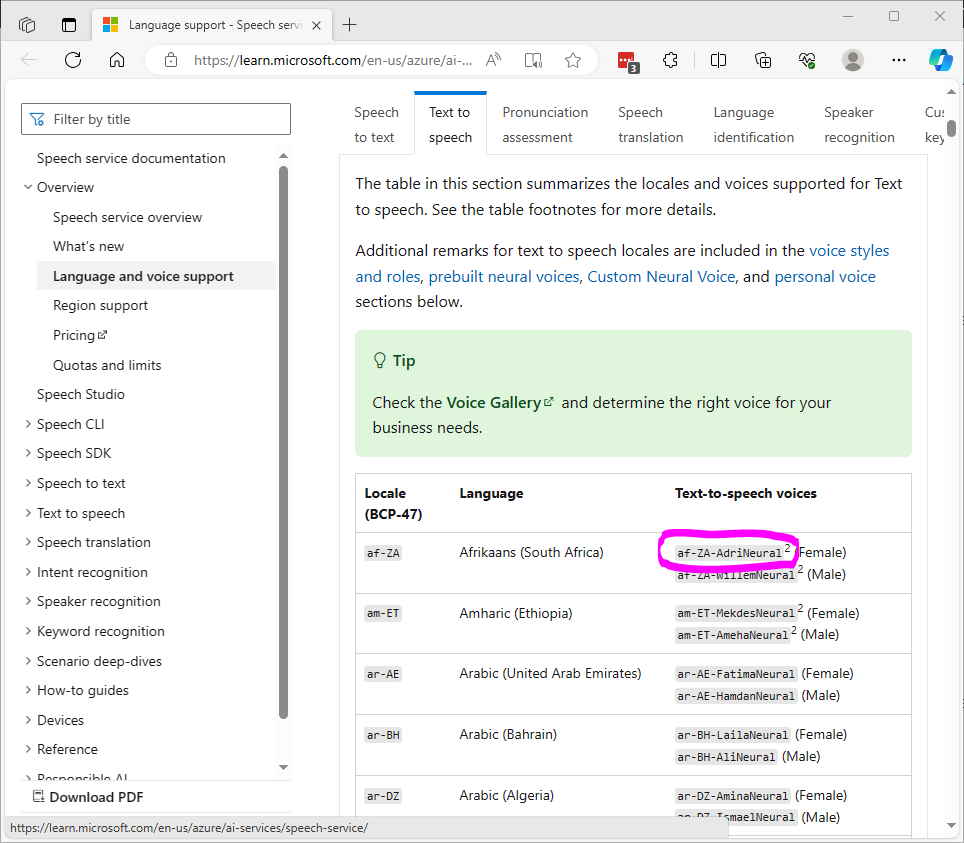
Microsoft provides a list of available voices for the Azure Text-to-Speech system here: https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=ttsWhen adding a voice to the configuration window from the above link, copy the greyed text on the right of the chart in the "Text-to-speech voices" column and paste it into the neural voice field. See this image below for the circled text as a demonstration. This text will be pasted to the neural voice field in the robot skill configuration screen to change the voice. There is also a ControlCommand to change the voice programmatically.
*Note: Using the "Speak" ControlCommand is recommended, as the SpeakSsml requires advanced understanding. The Ssml format can be researched on these links:
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-structure
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-voice
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-pronunciation
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-ssml-phonetic-sets
Example
This example will walk you through creating a simple project that speaks the entered text out of the PC speaker. Follow the instructions, and your computer will speak in any voice you configure!
Add the Azure Text To Speech robot skill to your project (Add robot skill -> Audio -> Azure Text To Speech).
Add a SCRIPT robot skill to your project (Add robot skill -> Scripting -> Script).
Edit the script robot skill and insert the following javascript code.
ControlCommand("Azure Text To Speech", "speak", "Hello i am speaking to you");
Save and close the script editor.
Press the START button on the script, and the robot will speak out of the PC speaker.
Press the CONFIG button on the Azure Text To Speech robot skill to view the configuration. Press the VIEW LIST link to view the available voices in this configuration window. Paste the voice that you wish to use into the neural voice textbox. Press SAMPLE if you want to hear a sample of the selected voice.
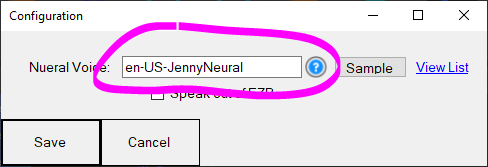
To change the voice programmatically (in code), you can send the control command. This example will change the default voice to US Jenny Neural.
ControlCommand("Azure Text To Speech", "setVoice", "en-US-JennyNeural");
How Does Speech Synthesis Work?
Text-to-speech (TTS) technology converts text into speech sounds through a complex process that involves several key components and techniques. Here's an overview of how TTS works:1. Text Analysis:
- The process begins with the analysis of the input text. This involves breaking down the text into smaller units, such as words, sentences, and paragraphs.
- The TTS system may also analyze punctuation, capitalization, and other text features to add appropriate prosody and intonation to the synthesized speech.
2. Linguistic Processing:
- Once the text is segmented, linguistic processing takes place to identify the text's phonetic, prosodic, and grammatical elements.
- The system determines the language, dialect, and pronunciation rules to be applied. It also identifies the stress and intonation patterns for each word and sentence.
3. Phoneme Conversion:
- Phonemes are the most minor units of sound in a language. The TTS system converts the linguistic information into a sequence of phonemes that represent the spoken sounds for the words in the text.
- Different languages have different phonemes, so the TTS system needs to know the specific language used.
4. Prosody and Intonation:
- Prosody refers to speech's rhythm, pitch, and stress patterns. Intonation includes the rise and fall of pitch in sentences.
- TTS systems use linguistic and contextual information to determine the appropriate prosody and intonation for the synthesized speech, making it sound more natural.
5. Acoustic Modeling:
- Acoustic modeling involves mapping the phonemes to their corresponding audio representations. This includes the selection of waveforms or audio samples for each phoneme.
- TTS systems use databases of pre-recorded phonemes or generate speech sounds synthetically using algorithms like concatenative or parametric synthesis.
6. Synthesis:
- The synthesized speech is generated by combining the acoustic representations of phonemes to create a continuous audio stream.
- TTS systems may apply techniques like concatenative synthesis (using pre-recorded phonemes), formant synthesis (generating speech based on the vocal tract's formants), or other methods to create the final speech output.
7. Articulation:
- The TTS system simulates the articulation of speech sounds, including the movement of the vocal tract and other speech-related organs, to create natural-sounding speech.
8. Output:
- The final audio waveform is generated and played through speakers or other audio output devices, making the synthesized speech audible.
It's important to note that the quality and naturalness of TTS output can vary based on the complexity of the TTS engine, the available linguistic knowledge and phoneme databases, and the quality of the acoustic modeling. Modern TTS systems, especially those based on deep learning techniques, have significantly improved in producing highly natural and expressive speech.
How Azure Text to Speech Works
Azure Text to Speech is a cutting-edge cloud-based service offered by Microsoft, designed to convert text into lifelike, natural-sounding speech. This powerful technology harnesses the capabilities of deep learning and neural networks to generate high-quality audio output from input text. With its extensive language and voice support, Azure Text to Speech provides a versatile solution for various applications, including human-robot interactions, accessibility, education, customer service, and more.The technology behind Azure Text to Speech is rooted in sophisticated machine learning models and neural networks. These models have been trained on vast amounts of multilingual and multitask supervised data, resulting in the ability to generate indistinguishable speech from human speech. Azure Text to Speech employs advanced natural language processing techniques to ensure accurate pronunciation and intonation, making the synthesized speech sound incredibly realistic.
Language and Voice Support
Azure Text to Speech offers one of the most comprehensive language and voice support libraries. Users can choose from many languages and dialects, allowing seamless communication with diverse audiences. Furthermore, voice customization options enable users to fine-tune characteristics such as pitch, speed, and even the emotional expressiveness of the generated speech.Text Formatting and SSML
To control the pronunciation, emphasis, and intonation of the generated speech, users can employ text formatting and Speech Synthesis Markup Language (SSML). This enables high customization, ensuring the speech output aligns perfectly with the intended message and context. Find out more information about the SSML format here...- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-structure
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-voice
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-synthesis-markup-pronunciation
- learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-ssml-phonetic-sets
Security and Compliance
Synthiam and Microsoft are committed to providing a secure and compliant environment for your data. Azure Text to Speech adheres to rigorous security and compliance standards to ensure your information is handled with the utmost care and responsibility.Use Cases and Industries
Azure Text to Speech has found relevance in various industries and use cases, including accessibility, customer service automation, education, entertainment, and more. Real-world examples and success stories showcase its versatility and impact. Enhance your experience with Azure Text to Speech by following best practices. Optimize text input, select the most suitable voice for your application, and maximize SSML for effective customization.Real-world case studies and testimonials from organizations and individuals who have experienced success with Azure Text to Speech can inspire and guide users in their ventures.
Limitations
The generated speech is limited to 500 characters per call and 1000 daily calls with an ARC pro subscription.Control Commands for the Azure Text To Speech robot skill
There are Control Commands available for this robot skill which allows the skill to be controlled programmatically from scripts or other robot skills. These commands enable you to automate actions, respond to sensor inputs, and integrate the robot skill with other systems or custom interfaces. If you're new to the concept of Control Commands, we have a comprehensive manual available here that explains how to use them, provides examples to get you started and make the most of this powerful feature.
Control Command Manual// Speak the provided text asynchronously in the background.
- controlCommand("Azure Text To Speech", "speak", "The text to speak as a string")
// Speak the provided text and wait for it to complete.
- controlCommand("Azure Text To Speech", "speakWait", "The text to speak as a string")
// Speak the provided SSML formatted text asynchronously in the background.
- controlCommand("Azure Text To Speech", "speakSsml", "ssml code as a string")
// Speak the provided SSML formatted text and wait for it to complete.
- controlCommand("Azure Text To Speech", "speakSsmlWait", "ssml code as a string")
// Set the voice to a new specified voice.
- controlCommand("Azure Text To Speech", "setVoice", "en-US-JennyNeural")
Related Questions
Cognitive Vision Not Speaking

Implementing Controlcommand For Talk Servo

Upgrade to ARC Pro
Become a Synthiam ARC Pro subscriber to unleash the power of easy and powerful robot programming
Works great thanks
tried a few voices
Ensure you have an internet connection when ARC is loaded. The list of available plugins requires internet connectivity to reach our servers. Additionally, if two copies of ARC are running at the same time, the plug-ins will not update because the files will be in use by the other copy of arc.
Additionally, you can scroll to the top of any robot skill page and press the large "Get Version X" button.
For some reason windows no longer had an association of .ezplugin files with the plug in manager. Re-associated the files and now installed correctly.
All works here
here are some voices here is all the voices https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts#voice-styles-and-roles
Updated v3 to capture the error for when testing a voice by name that does not exist in the config menu.
V7 updated...
Read the manual above for more information.
We have updated the manual above to explain what part of the voice list to copy and paste into the configuration of this robot skill.