
Cloud-based detection of people and faces in robot camera video; returns locations, gender, age, pose, emotion, plus 68-point facial landmarks.
 Source Code
Source CodeHow to add the Sighthound Cloud API robot skill
- Load the most recent release of ARC (Get ARC).
- Press the Project tab from the top menu bar in ARC.
- Press Add Robot Skill from the button ribbon bar in ARC.
- Choose the Camera category tab.
- Press the Sighthound Cloud API icon to add the robot skill to your project.
Don't have a robot yet?
Follow the Getting Started Guide to build a robot and use the Sighthound Cloud API robot skill.
How to use the Sighthound Cloud API robot skill
The Sighthound Cloud Detection API returns the location of any people and faces found in robot camera video. Faces can be analyzed for gender, age, pose, or emotion; and a landmark detector can find the various facial features in the detected faces, including eyes, nose and mouth, by fitting 68 landmark points to those features.
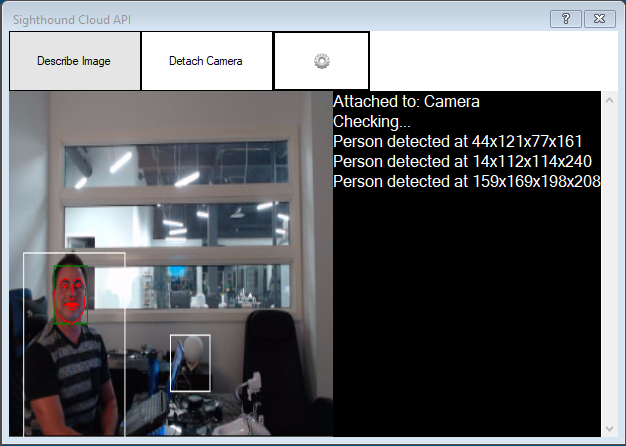
*Requirement: This plugin requires ARC 2019.12.11.00 or higher
Variables are set with information that has been detected.
This plugin requires a Camera control to be added to your project. The image that will be detected will come from the camera control.
Lastly, you will require an account with www.sighthound.com. There is a free demo account that you can configure which limits the number of calls.

Very nice. Can detect faces even on very low (160 x120) resolution!
Really? That's great! Did it detect the features of the face at that resolution? I think it'll be neat to return the face features as coordinates so people can calculate face features as well. Have a few ideas for this control
It was off just slightly in the overlay but captured mouth eyes and nose with jaw and I had a hat on! All other resolutions are perfect match.
I look forward to what you have up your sleeve!
Hi,
You say we can get the person count, gender, age, pose, and emotion with SightHound. Yet, I only am able to get the # of people and the gender. There seems to be no variables available for age, pose, or emotion. Also, the pose variable says "True." What am I doing wrong? Have those features been removed from the skill?
Thomas Messerschmidt
You will have better luck visiting the author's website to view their product information.