

Watson Speech-to-Text ARC plugin: cloud AI transcription with configurable models, selectable VAD (Windows/WebRTC), audio capture and visualization.
How to add the Watson Speech To Text robot skill
- Load the most recent release of ARC (Get ARC).
- Press the Project tab from the top menu bar in ARC.
- Press Add Robot Skill from the button ribbon bar in ARC.
- Choose the Audio category tab.
- Press the Watson Speech To Text icon to add the robot skill to your project.
Don't have a robot yet?
Follow the Getting Started Guide to build a robot and use the Watson Speech To Text robot skill.
How to use the Watson Speech To Text robot skill
Watson Speech to Text is a cloud-native solution that uses deep-learning AI algorithms to apply knowledge about grammar, language structure, and audio/voice signal composition to create customizable speech recognition for optimal text transcription.
Get Version 11
Version 11 (2020-11-03)
compatibility with ARC's new version
Version 10 (2020-10-20)
Minor changes
Version 9 (2020-10-08)
I decided to break the plugin in multiple plugins to help troubleshooting, improve and fix bugs. This plugin will become Watson Speech to Text.
Documentation (WIP) You will need an IBM cloud account (Free Tier)
Watson Speech To Text: https://www.ibm.com/cloud/watson-speech-to-text
Register a new account: https://cloud.ibm.com/registration
login to your account: https://cloud.ibm.com/login
Dashboard:
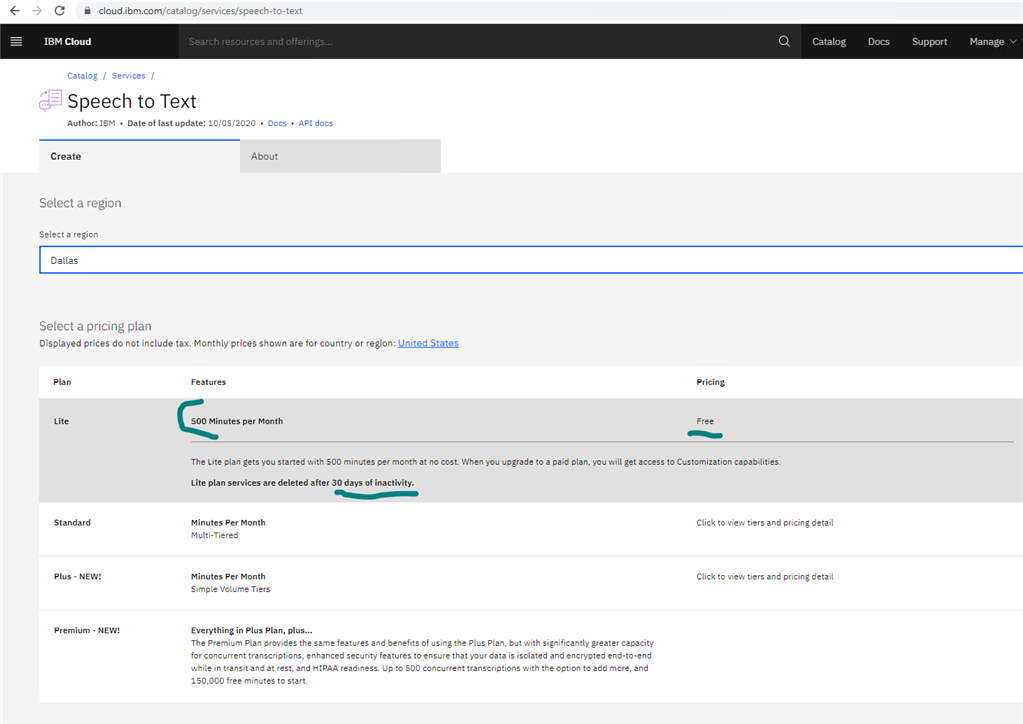
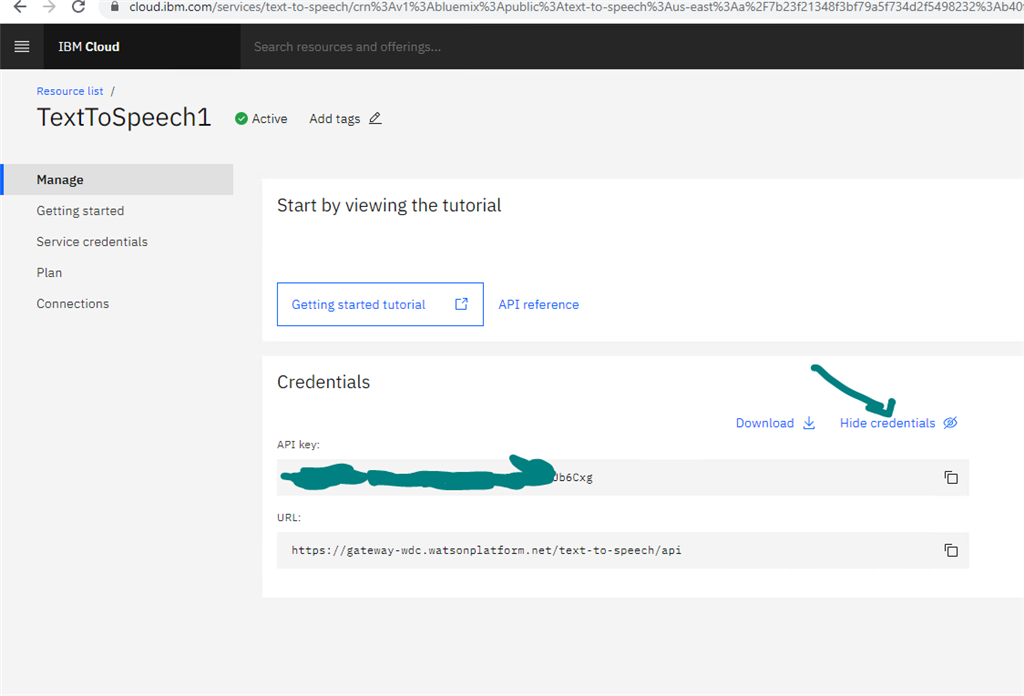
after creating or managing the service's credentials:Quote:
The Lite plan gets you started with 500 minutes per month at no cost.
Plugin Configuration:

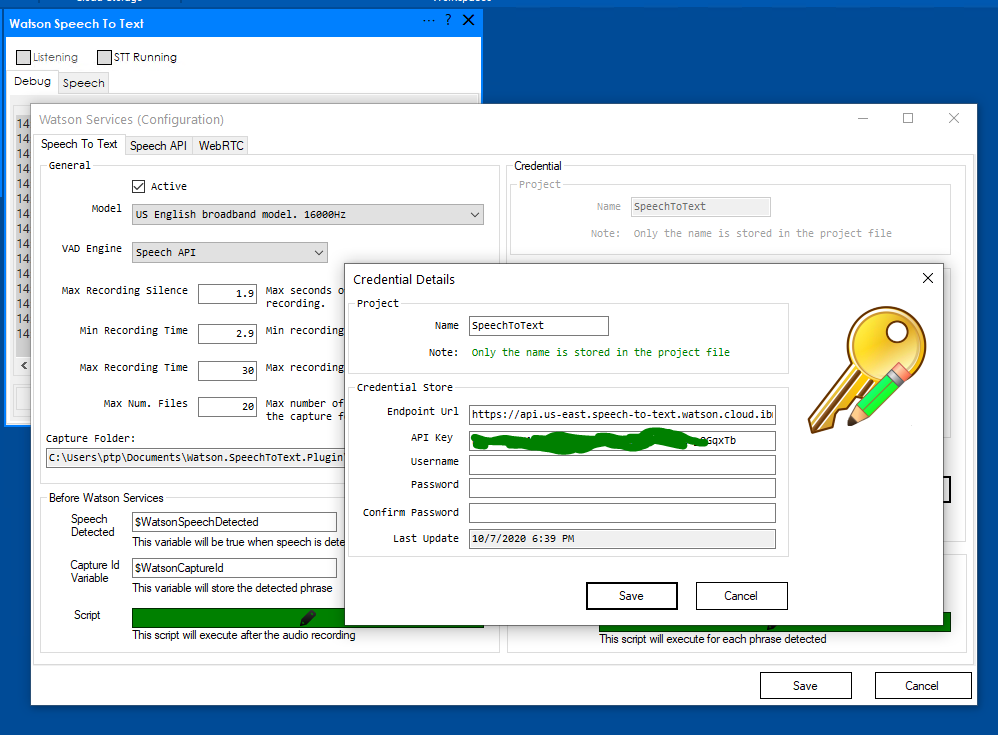
You will need to configure the model i.e. Language choose high rates i.e. 16000 for better quality capture:
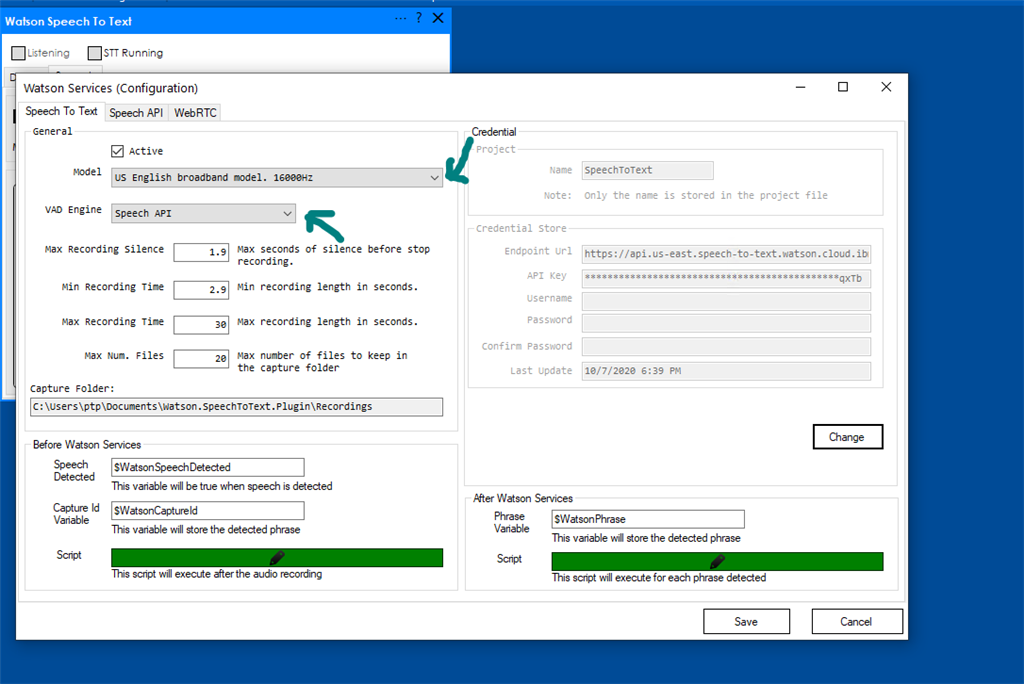
You will need to select a VAD (Voice Activity Detection) engine, this engine handles the speech detection the plugin supports two different engines: Speech API available on Microsoft Windows and WebRTC engine.
Windows VAD engine configuration:
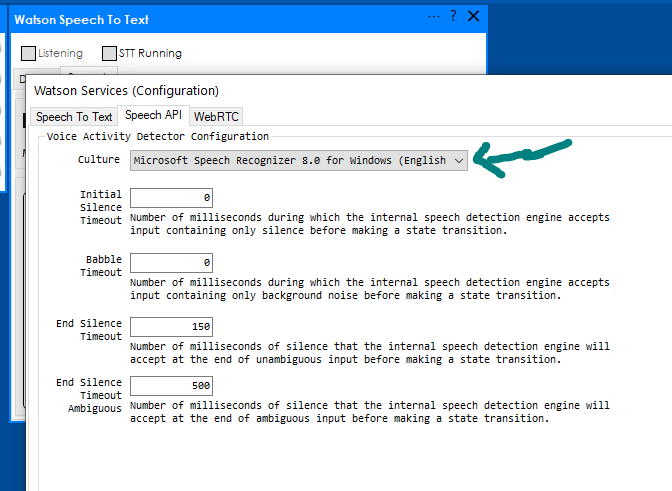
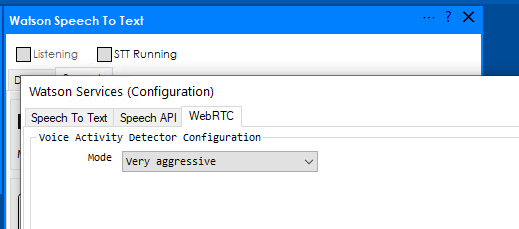
Speech Tab:
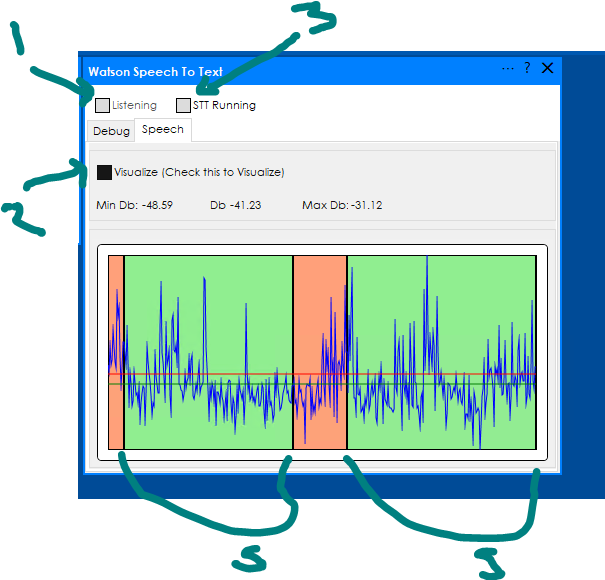
- The plugin will be listening i.e. Capturing Audio when the Listening checkbox is checked)
- The plugin will show audio visualization when the Visualize checkbox is checked To listen and visualize you don't need a Watson service account configured.
To use the Watson cloud services you will need to check the STT (Speech To Text) checkbox.
Green Areas are flagged with speech and orange areas are silence / noise.


When I load the skill this error appears:
what am I wrong?
thanks!
Same thing as this plug-in, but a different Author
@lucdag: I'll update the plugin during the weekend.
Nice thanks PTP I really appreciate you keeping this plugin updated :-)
quick feedback: I got delayed with some issues relating to the development tools upgrade, but I'm almost done.
@Nink: No problem.
There are new improvements, one of them is a translation service, I plan to add to the plugin.
Hello. I am waiting for the update as well.
Thanks for all of your good work!
New version released ! Still doing tests and trying to catch new bugs.
New version released, please check the "breaking changes".
I'll start releasing the other Watson services plugins soon: TextToSpeech, Visual Recognition, Assistant and Language Translator