

Microsoft Cognitive Vision integration for ARC: real-time object, face, emotion detection, OCR, confidence data and script-triggered robot actions.
How to add the Cognitive Vision robot skill
- Load the most recent release of ARC (Get ARC).
- Press the Project tab from the top menu bar in ARC.
- Press Add Robot Skill from the button ribbon bar in ARC.
- Choose the Camera category tab.
- Press the Cognitive Vision icon to add the robot skill to your project.
Don't have a robot yet?
Follow the Getting Started Guide to build a robot and use the Cognitive Vision robot skill.
How to use the Cognitive Vision robot skill
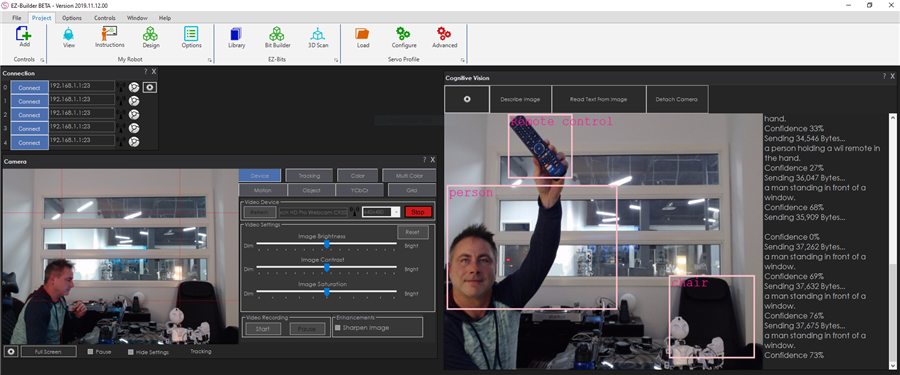
- Describe a scene (example: “a person standing in a room”).
- Read printed text in an image (OCR).
- Return extra details such as object locations (boxes), sizes, and content flags (ex: adult content indicators).
Beginner Overview (How It Works)
Think of this skill as a “smart helper” for your robot’s camera. Your camera provides a picture (a single frame). Cognitive Vision uploads that image to Synthiam, Synthiam analyzes it using machine learning, and ARC stores the results in variables that your scripts can use.
Typical flow
- Add a Camera Device to your ARC project.
- Add the Cognitive Vision Robot Skill.
- Press Detect (to describe the image) or ReadText (to read text).
- The skill fills in configured variables (scene description, confidence, read text, and arrays of object details).
- Optional: ARC runs a script automatically after the result is returned, so your robot can speak or react.
What You Need Before You Start
- Synthiam ARC installed (ARC Pro recommended).
- A working Camera Device in your project (USB camera, IP camera, etc.).
- Internet access on the computer running ARC (or on the robot setup, depending on your configuration).
Recommended Tools
- Variable Watcher to see values update live.
- ARC scripting (to speak results or trigger actions).
Adding Cognitive Vision to a Project (Step-by-Step)
-
Add a Camera Device
Follow: Camera Device tutorial. Confirm you have a live image. -
Add the Cognitive Vision Robot Skill
Add it from the Robot Skills list, then open it so you can configure its settings. -
Select/attach the camera
The skill must be connected to the camera you want to analyze. If you have multiple cameras, choose the correct one. -
Test with “Detect”
Use the Detect button/command to generate a scene description and object data. -
Test with “Read Text”
Place readable text in view (paper sign, label, etc.) and run ReadText to populate the text variable.
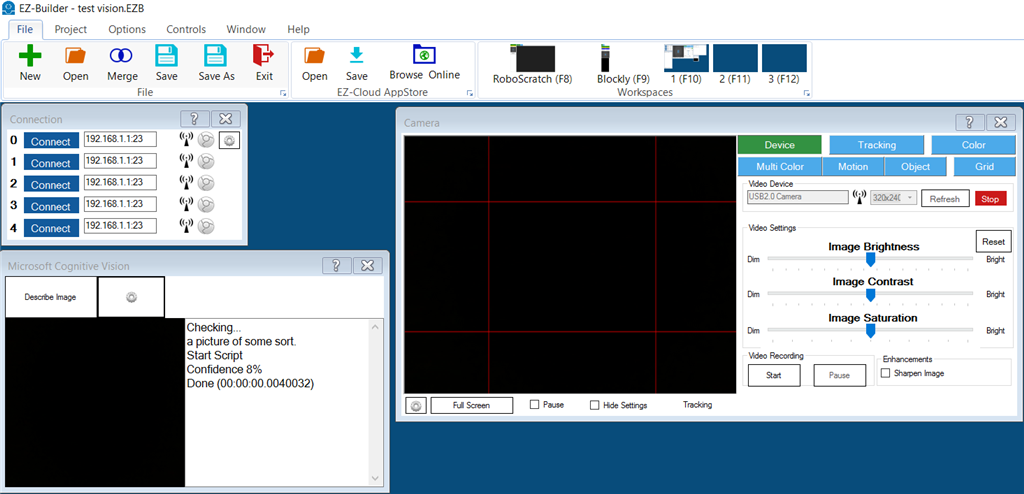
Understanding the Results (Variables and Arrays)
After a Detect or ReadText request finishes, the skill stores results in variables (and arrays) so other skills and scripts can use them. The easiest way to see these values is to open the Variable Watcher.
Common result values
- Detected Scene (variable): A plain-language description of the image (filled after Detect).
- Confidence (variable): How confident the service is in the scene description (higher is more certain).
- Read Text (variable): The text found in the image (filled after ReadText).
- Object arrays (advanced): For each detected object, the skill stores width/height and location data (useful for tracking where an object is in the image).
- Adult content indicators: The analysis includes content classification flags intended for safety filtering.
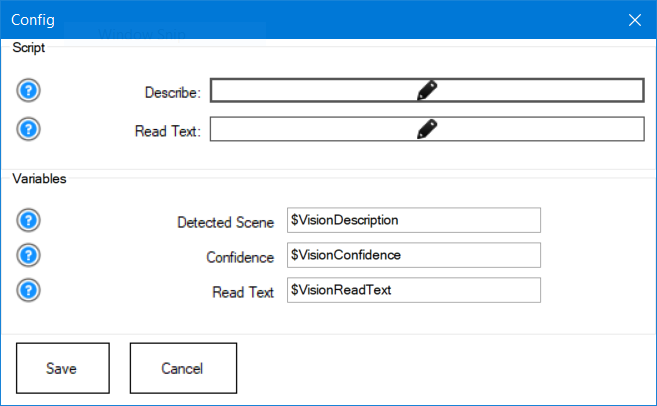
Configuration Menu (What Each Setting Means)
The configuration menu lets you define which scripts to run after results are returned and which variables should receive the data. If you change variable names here, make sure your scripts use the same names.
Scripts (run automatically)
-
Describe
Runs after a Detect completes. Use it to speak the scene, move the robot, or make decisions using the detected data. -
Read Text
Runs after ReadText completes. Use it to speak the text or trigger actions (example: if the sign says “STOP”, stop the robot).
Variables (store the results)
- Detected Scene: the description of the image after Detect.
- Confidence: confidence value for the scene description.
- Read Text: text extracted from the image after ReadText.
Using Scripts (Beginner Examples)
Scripts let you turn vision results into robot behavior. For example, you can have your robot speak what it sees using the scene description variable.
Example: speak what the camera sees
Add this to the skill’s Describe script so it runs automatically after Detect:
Say("I am " + $VisionConfidence + " percent certain that I see " + $VisionDescription)
Sample project: testvision.EZB
Control Commands (Use from Other Skills or Scripts)
You can trigger Cognitive Vision from anywhere in ARC using ControlCommand(). This is useful if you want another skill (like speech recognition,
autoposition, or a timer) to request a vision update.
Available commands
Detach — disconnect the skill from the current camera
ControlCommand("Cognitive Vision", "Detach");
Detect — analyze the current camera frame and populate description/object variables
ControlCommand("Cognitive Vision", "Detect");
ReadText — read text (OCR) from the current camera frame and populate the text variable
ControlCommand("Cognitive Vision", "ReadText");
Video Tutorials
Educational Tutorial
This tutorial shows how to use Cognitive Vision with a camera in ARC.
Demo (Cognitive Vision + Conversation)
Example project combining Cognitive Vision, Pandora Bot, and speech recognition for interactive conversations.
Limited Daily Quota (Important)
Troubleshooting (Beginner Checklist)
If Detect/ReadText returns nothing
- Verify your Camera Device shows live video.
- Confirm you have an internet connection.
- Check the Variable Watcher to see if variables update.
- Make sure you’re using the correct action: Detect for scenes/objects, ReadText for OCR.
If results seem inaccurate
- Improve lighting and reduce motion blur.
- Move closer to the object or text.
- Use the Confidence value to ignore weak guesses.
- For text: ensure it’s large enough, high-contrast, and not heavily angled.
Related Questions
Detect Multiple Face From EZ Blocky Logic
Cognitive Vision Not Speaking

Choosing Right Camera FOV

Upgrade to ARC Pro
Join the ARC Pro community and gain access to a wealth of resources and support, ensuring your robot's success.
I just watched the videos on these services and tried to set up a text read and he just says he is 87 percent he sees the words..but not the actual words. Any one with pointers to get this to work? I tried both hand written and typed words. Do they need to be a certain size? Or this service from microsoft needs work?
*Notice the space after "words"
How did I miss that..cross eyed! Thank you ..once again! Must sleep..
...odd the new version filters adult content?! How is that a feature? What was Microsoft trying to prevent/use cases? Especially if you think of all the other filters they could have added for whats found in an image.
I don’t believe there’s any filtering being done. There is a value of how much adult content there is, but I don’t believe anything is filtered
you can always stand nude in front of your robot to test it out hahaha
Yeah your right not a filter more of a tag. Still wondering why that’s a "feature" . Why not something useful like " cats chasing dogs?
I did a little research earlier today and it’s possible to create custom object detection projects. Train and prediction. Makes it more useful for a case by case robot.
..of course I got naked in front of the vision cognition ...it said "'100% sure you should put your clothes back on!'" Lol.
Ya it’s a rating - it’ll help some applications to prevent abuse. I know we’re using it for a new service we’re releasing in beta next week.
ill take a look at the custom detection part. Although it is quite easy to do local with the object tracking built in the camera control
Looking forward to that beta!