

Tiny YOLOv3 CPU-only real-time object detection using a camera; offline detection, script-triggered on-changes or on-demand results with class/scores.
How to add the Darknet YOLO (Obj Detection) robot skill
- Load the most recent release of ARC (Get ARC).
- Press the Project tab from the top menu bar in ARC.
- Press Add Robot Skill from the button ribbon bar in ARC.
- Choose the Camera category tab.
- Press the Darknet YOLO (Obj Detection) icon to add the robot skill to your project.
Don't have a robot yet?
Follow the Getting Started Guide to build a robot and use the Darknet YOLO (Obj Detection) robot skill.
How to use the Darknet YOLO (Obj Detection) robot skill
You only look once (YOLO) is a state-of-the-art, real-time object detection system. using Tiny YOLOv3 a very small model as well for constrained environments (CPU Only, NO GPU)
Darket YOLO website: https://pjreddie.com/darknet/yolo/
Requirements: You only need a camera control, the detection is done offline (no cloud services).
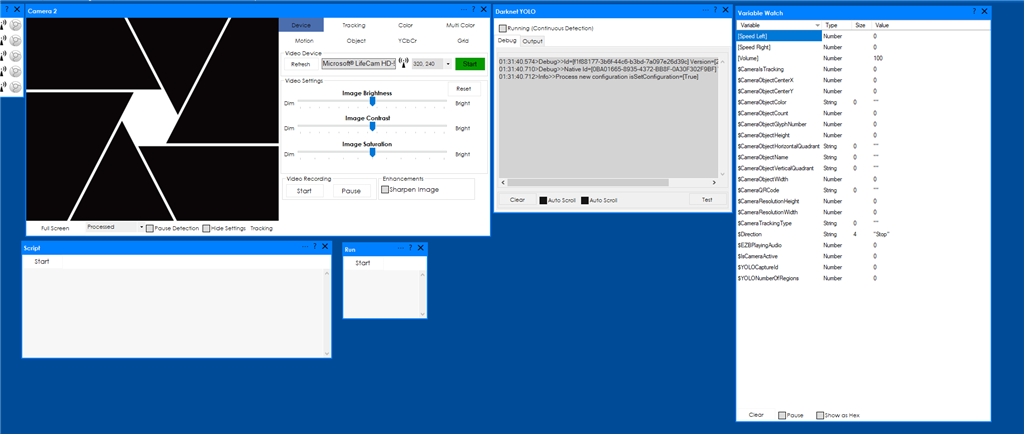
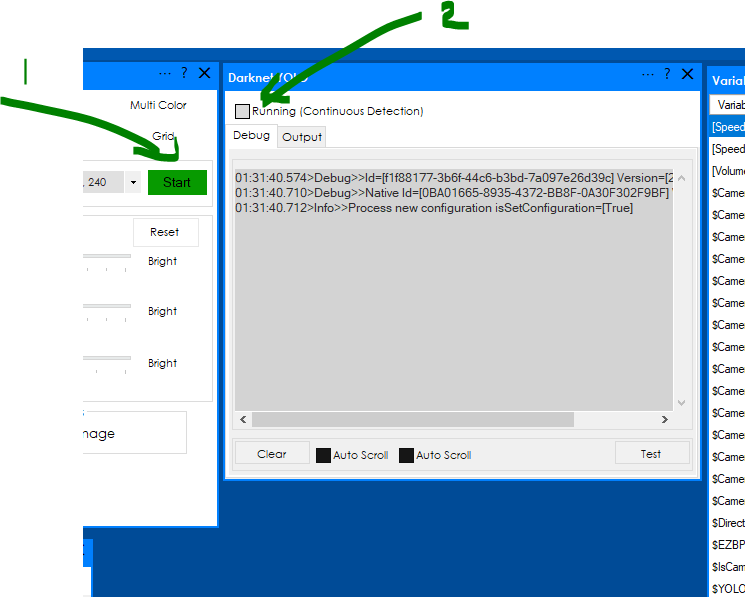
- start the camera.
- check the Running (check box)
The detection will run continuously when the detection results change an On Changes script is executed (check the configuration area):

- Press config
- Edit the on changes script
- on changes Javascript script
you can run the detection on demand, javascript:
controlCommand("Darknet YOLO", "Run");
The above command runs the configured on demand script.
An example of script:
var numberOfRegions=getVar('$YOLONumberOfRegions');
if (numberOfRegions==0)
{
Audio.sayWait('No regions found');
}
else
{
Audio.sayWait('Found ' + numberOfRegions + ' regions');
var classes = getVar('$YOLOClasses');
var scores = getVar('$YOLOScores');
for(var ix=0; ix {
Audio.sayWait('Found ' + classes[ix] + ' with score: ' + (classes[ix]*100) + '%');
}
}


DJ: quick search: https://docs.microsoft.com/en-us/dotnet/api/system.drawing.bitmap.-ctor and I'm guessing is a shallow copy not a deep copy, so the "shell" object is different but the byte buffer is the same. So soon or later becomes an issue. I'll change the code, looking for elegant e.g. (less boiler plate code) to generate a deep clone.
EDITED *** I did not see the previous post ** Thanks!
Here - you might find these handy... They exist in EZ_B.Camera
Very nice work ptp. I am interested to know what tools/languages you used to build this, if you have the time that is. I love Yolo...seems to work pretty well in near dark lighting conditions too. I've been using the 80 class version. My favorite is when it recognizes my cats, plants, phones, and tvs. I don't know why but it continues to amuse me, I think because I know I would never be able to do it without a NN. It feels like magic. I keep hoping someone in the industry will build some more Yolo-like models with a lot more classes. It seems like I read about a Yolo9000 but was never was able to find anything I could use. If anyone finds a model with a lot more classes, I'd love to hear about it. I haven't tried v4 or v5 yet...I don't think anyone has published one beyond v3 that will deploy on a Movid.
Ptp did a great job - works well! If you’re interested in having a larger trained dataset, there’s a global version here: https://synthiam.com/Support/Skills/Camera/Cognitive-Vision?id=16211
it uses a worldwide database of trained stuff. And you get a description of the scene that’s neat. You can feed that into nlp for topics of the surroundings.
Hey PTP this looks amazing, will give it a try, hopefully works well when people detected coming through main door and use enhanced script to have some fun with intruders!
Sorry the delay, I've been underwater with work.
@Guys: Thanks for the good words
@Martin:
Short answer: Visual Studio Community/Enterprise 2019ARC plugins are .NET The main plugin dll is a visual studio c# .NET class project and I've two other additional projects in c++. ARC is a 32 bits application so when you combine low level code (c++) or external native libraries and .NET you need to take that in consideration. Sometimes you need to compile from source, and fix or tweak the open source code to use msft building environment.
If you need more details my email is in the profile.
@DJ:
When I start playing with object detection, I wanted something to monitor a live video feed and trigger actions based on objects. All the cloud APIs have limits so is not feasible to use the online services.I presume your skill has a limit cap ?
Also the model is a Tiny version optimized for CPU, so the accuracy is lower than the full models (Nvidia GPUs).
The biggest challenge is to find optimized models for our needs, for example I'm using this model to track the deliver man. I don't expect a train, horse, sheep, cow, elephant, bear, zebra, giraffe in the camera But the model supports those categories.
But the model supports those categories.
The solution is to train your model with your images. I'm capturing pictures of the deliver guy, and I want to expand the capture to the trucks. Maybe later I can train a model to detect UPS, Fedex, USPS, DHL, Amazon trucks
Until then... I've a trigger to alert me if an Elephant arrives at the door.
Spotting Elephants here in Alabama could be useful as its the mascot for the University of Alabama. BTW, there is no pressure to ever answer anything from me, timely or at all. I am just thrilled at any answer at all on any timeframe.
For me, I am proceeding along the following path with darknet object detection:
1. I implemented Darknet as you know, and it is returning good bounding boxes and probabilities for the 80 classes. When I mentioned having a better model...I meant I wanted more classes.
2. I implemented a skill to get the robot to tell me what it sees by saying "What do you see?". 3. I am wondering if there is a way to augment DarkNet with AlexNet. To this ends, I first implemented the AlexNet model (1000 classes). The problem here is AlexNet classifies an image as a single thing, so I need to figure out an algo for picking subsets of an image that might contain single interesting objects. Until I figure out now to do that, AlexNet is not all that useful to me unless the bot is leaning over, staring directly at something and trying to identify or pick it up. Also, a huge amount of the 1000 classes are still biology or other fairly useless classes like you pointed out. There are a lot of alternatives to AlexNet that all have these same issues...single object and too many useless classes like species. Species aside, does anyone know a good way to segment an image so parts of it can be classified?
4. Here are the use cases I want to focus on next... more verbal questions and answers (about what is seen) like "Where is the cat?", "How far away is the cat?" (depth sensor), "How big is the cat." (some trig with distance and bounding box), "What color is the cat?" (image processing, tougher one for me), "Shoot the cat." (lasers), "Go to/chase the cat" (nav/drive), "Point at the cat." (servos), "What is next to the cat", "How many cats do you see?", "Look at the cat", "What is the cat on top of?" (table, tv, etc.) and others. You get the idea. While some of these sound challenging or error prone, almost all of these are achievable. I'd like to make a vid when I get some of these going.