
PRO
afcorson
Australia
Asked
Silence Detection For Bing Speech Recognition Skill
I thought I had requested this feature before, but I can't find any record of it. I would like the Bing Speech Recognition Skill to detect when a person stops talking and then stop recording. VAD is not that reliable and limiting the recording length is a clumsy way to stop the recording. For example if the recording limit is set to 7 secs and the user just says 'hello robot', they would be waiting several seconds before getting a response, by which time they have probably walked away.
Related Robot Skills (view all robot skills)

Bing Speech Recognition
by Microsoft
Accurate Bing cloud speech-to-text for ARC: wake-word, programmable control, $BingSpeech output, Windows language support, headset compatible

Voice Activity Detection
by Synthiam
Real-time microphone VAD using FFT to detect speech start/end and trigger scripts, with live level graph and sensitivity tuning
Requires ARC
v9

The VAD robot skill will be helpful for your usage. The manual for it is here: https://synthiam.com/Support/Skills/Audio/Voice-Activity-Detection?id=20215
An example provided will start/stop a speech recognition robot skill upon detecting speech. In your case, add the ControlCommand to instruct Bing to Start Listening when a voice is detected. Add another ControlCommand to Stop Listening when the voice ends. You can add these commands to the scripts of the VAD robot skill.
What you request from Microsoft Bing's Speech Recognition does not exist further than what is presented. There are limitations to software created by third parties. In the case of a limitation that does not fit your requirements, an additional skill is necessary.
I made no request relating Microsoft's Bing Speech Recognition. The feature request relates to ARC's Bing Speech Recognition. My robot only listens when WaitForSpeech is invoked, or Bing Speech Recognition is started. I have no need to use the Speech Recognition Skill. The VAD Skill may well help stop Bing Speech from listening when no sound is detected. I will do some testing. Also I found no provision to adjust sensitivity in the VAD Skill.
Ah, the support agent was correct. Microsoft makes Bing Speech Recognition. The company/manufacturer of the robot skill is listed on its respective manual pages.
This is a good solution since the Microsoft Bing Speech Recognition can't be modified. Give their suggestion a read again, it makes sense.
I don't know what "sensitivity" you'd be looking for. Speech is not a sensitivity value because it's either there or not. I think the value of "how long of silence" might be helpful. You can read how VAD works here: https://en.wikipedia.org/wiki/Voice_activity_detection
It's a pretty complicated thing. I think most people think of sound as a wave with a volume level. But it's a waveform with complex peaks and valleys that have a unique signature to the type of sound. If you examine the waveforms, the sound of a human voice is different than that of a car, etc. There's a lot math in there - and sensitivity isn't a thing for something like that. The algorithm is "yes" or "no", which will also present false positives for both cases because nothing's perfect.
Also, the other thing to consider is understanding why all your Google Home/Alexa/Siri devices have Wakewords. The device is not listening for speech. It's listening for a particular pattern that matches one stored pattern to be triggered. That's why VAD is such a tricky thing, and Alexa, Siri, Google Home, etc, do not use VAD. They use a wake word.
@Athena give some details on VAD to expand on what I wrote.
That is correct. The robot skill's name is Bing Speech Recognition, but the company that makes it is Microsoft. While the Bing Speech Recognition robot skill manual does not explicitly display the manufacturer as DJ suggested, it was created in partnership with Microsoft. Bing is a trademark of the Microsoft Corporation, not just a search engine.
The solution we presented was tested after your feature request. The robot skill VAD was updated for improved performance. Your request was given several man-hours of attention, and a solution was presented. We hope it fulfills your requirements.
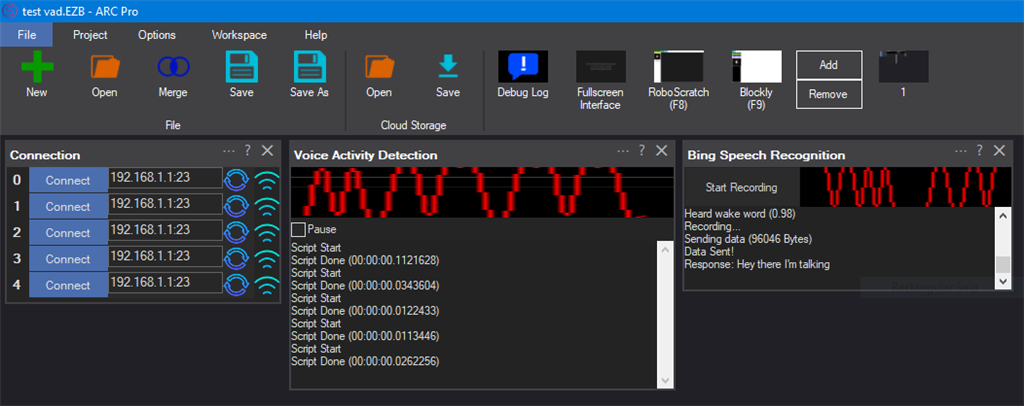
I just tested their solution and it works fantastic - great idea! What I did was tweak it a little. I don't like VAD detecting the START of a speech. I want to use a wakeword. So in this case I only used this VAD robot skill to instruct Bing Speech Recognition to STOP LISTENING. I left the "Start Listening" VAD script empty.
Here's the project I created for my test. Works awesome: test vad.EZB
It sounds like you're on the right track with using the Voice Activity Detection (VAD) skill to manage when the Bing Speech Recognition skill starts and stops listening. This approach can help improve the responsiveness of your robot by stopping the listening process when no speech is detected, thus avoiding unnecessary waiting times.
Steps to Implement VAD with Bing Speech Recognition:
Configure VAD to Stop Listening:
Start Listening with a Wake Word:
Testing and Adjustments:
Example Script for VAD:
Voice Stop Script:
Voice Start Script:
Additional Considerations:
Sensitivity Adjustments:
Wake Word Implementation:
If you have any further questions or need additional assistance, feel free to ask!
Thanks for the info. In testing the VAD Skill, I found it did nothing, just a red squiggly line. However, when I spoke loudly, suddenly it worked. So the sensitivity feature mentioned in the Skill doco would be useful - see below... The VAD Skill will stop Bing Speech Recogntion, as long as I am speaking loudly (on my setup).
Key Features: Speech Detection: Detects when speech starts (Speech Begin) and stops (Speech End). Customizable Actions: Allows users to attach custom scripts that execute automatically when speech starts or stops. For example, you can trigger robot movements, lights, or other interactions based on speech activity. Real-Time Audio Visualization: Displays a live graph of the detected speech level, giving a visual representation of the audio activity. Adjustable Sensitivity: Includes settings to fine-tune detection parameters, such as silence thresholds, for optimal performance in various environments.
I should be able to adjust the Mic input level in Windows Settings to achieve the correct sensitivity level with the VAD Skill.