
PRO
afcorson
Australia
Asked
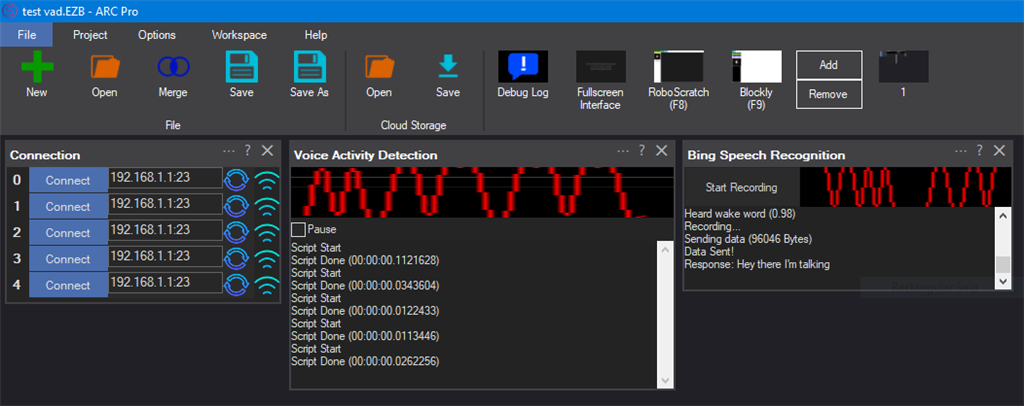
Silence Detection For Bing Speech Recognition Skill
I thought I had requested this feature before, but I can't find any record of it. I would like the Bing Speech Recognition Skill to detect when a person stops talking and then stop recording. VAD is not that reliable and limiting the recording length is a clumsy way to stop the recording. For example if the recording limit is set to 7 secs and the user just says 'hello robot', they would be waiting several seconds before getting a response, by which time they have probably walked away.
Related Robot Skills (view all robot skills)

Bing Speech Recognition
by Microsoft
Accurate Bing cloud speech-to-text for ARC: wake-word, programmable control, $BingSpeech output, Windows language support, headset compatible

Voice Activity Detection
by Synthiam
Real-time microphone VAD using FFT to detect speech start/end and trigger scripts, with live level graph and sensitivity tuning
Requires ARC
v9

I just wanted to chime in here and validate @afcorson 's request. I also found that the timed stop listing function in Bing Speech was problematic.
I have my Bing set to a wake word, no VAD and a 5 second time set to stop listening. I have only one command that takes over 5 seconds (7 actually) and many that much less then 5 seconds. If I want Bing to catch the 7 second command this means I need to set the timer to 7 seconds and the much shorter commands will have a very long pause before something happens. I'm just stating all this to be clear and support afcorson.
I really appreacheate @Customer Support and @DJ putting in the work on afcorson 's request. I'm looking forward to testing this myself. If it works for me it will ba a game changer in the appearance of lag in the response of my robot using Bing Voice Commands. I mainly control most everything with Bing Speech. Thank You!
Thanks for those comments. I often use Bing Speech Recognition to communicate with ChatGPT. The person operating the robot could be asking anything which takes 1 sec or 9 secs. That's why it's important to stop listening as soon as they have stopped talkng. It will be even more important when ChatGPT 4-o realtime is available and affordable using audio input.
I dig that you’re pushing for technology that fits your specific scenario, but I don’t know if that technology can do what you’re requesting. If Amazon or Google can’t do it, you won’t see it anywhere else.
Here's why-and to be clear, it can be done with faster real-time AI processing someday.
but here’s why: listening is a conscious act. Our human brains can differentiate multiple sounds and voices to focus on one and interpret it in real-time. Remember, speech and other noises are the same thing-they’re sound. Sound is sound. It’s waveforms. You have to sample the waveform and process it afterward.
After the speech has been completed, it’s not processed in real-time like your brain.
Speech is a sound. The VAD isolates a waveform frequency range through a filter. Then, it tracks how long the filtered waveform is above a specific decibel level compared to the sampled noise floor. The floor is also an average of the sound within the filtered range.
Okay, now the filtered waveform decibel peaks within the sample size exceed the noise floor for a time. That must mean there’s speech.
By this point, we’ve already lost most of the first bit of speech. But it’s now recording
Okay, now there’s more difficulty understanding when the speech stops.
It can be known, but only after a period of time. The period is based on how long the speech is being recorded. Also, the time to maintain an average above the floor is not always accurate for all speech.
For example, several words have quiet parts to them. Specifically, words have spaces of silence between them. In addition, pauses to think of the next word vary between humans.
That's why I said it’s a conscience thing to understand when someone has finished speaking. We also use our eyes, but that’s a different subject.
So, if you were to assume every human across the planet spoke the same volume with the same silence between words - you could more accurately do what you want.
This is why your Alexa, Siri, or Google will cut you off as you’re speaking. They don’t know when you’ve finished, either. It’s just impossible to know at present without real-time processing, which doesn’t exist with current computing capability.
I'm guessing the developer could add parameters for silence and sound timing-because it should be possible. But right now, I know it’s self-adjusting.
I’ll poke them and see if they can add those parameters for you to hardcore. It’ll be a waste of effort, but I’ll have them do it anyway. Once you see what hardcoding will do, you’ll most likely want to use the auto setting.
I tested this skill yesterday, and it works wonderfully. So, I’m more curious about why your setup doesn’t work. Perhaps some effort is necessary to improve your mic type, position, and volume levels.
We can add the parameters for adjusting the silence timeout rather than having it calculated. We meant to do this in yesterday's release but ran into several issues, so we stuck with the calculation used in widespread instances of this feature.
The primary failure points we noticed are mic types (quality), background noise, input volume, and location. Devices such as Amazon Alexa are manufactured for specific hardware from Amazon, for example. This allows them to control the hardware, mic quality, etc.
We tested with a Jabra Conferencing mic designed for that usage. General mics are for audio specifically and are not fine-tuned for speech. A general mic on a laptop or handheld is designed to record everything from music to sound effects to speech. Having a mic designed for speech helps remove false positives.
I think the solution that everyone uses, such as those Sophia robots, is to use a microphone with a push button.
Press and hold the button to record and release it when stopped. Use a looping script to monitor the state of a button. Start and stop recording appropriately.
DJ, were you thinking of something like this? In this example, the switch for the mic would be on port d0.
Yes yes - just like that. I think the bing speech recognition should have a variable set when it is listening and processing. That would be useful for scripts not to bother doing something when it's being processed.
Today I did some further testing of speech recogntion and the VAD Skill using two new USB mics. Whilst speech recogniton worked perfectly for both microphones, I had to yell into the Mic to get a green line in the VAD skill. I do wish it had adjustable sensitivity as alluded to in the documentation for this skill.