
PRO
afcorson
Australia
Asked
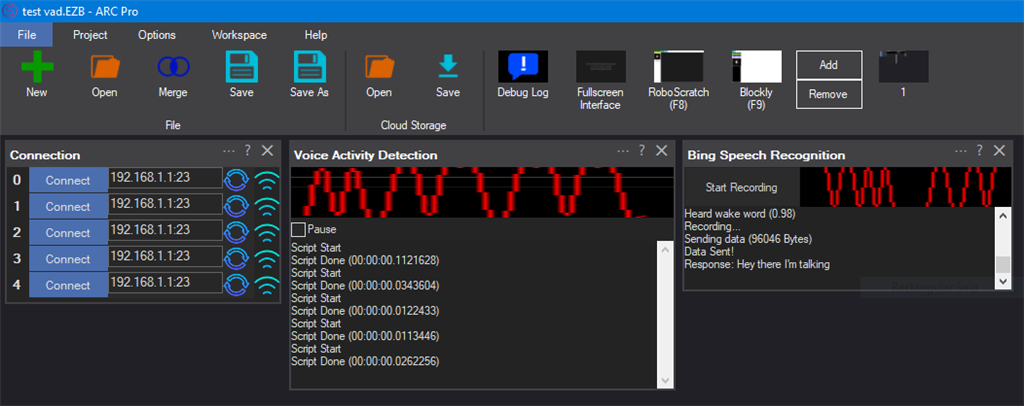
Silence Detection For Bing Speech Recognition Skill
I thought I had requested this feature before, but I can't find any record of it. I would like the Bing Speech Recognition Skill to detect when a person stops talking and then stop recording. VAD is not that reliable and limiting the recording length is a clumsy way to stop the recording. For example if the recording limit is set to 7 secs and the user just says 'hello robot', they would be waiting several seconds before getting a response, by which time they have probably walked away.
Related Robot Skills (view all robot skills)

Bing Speech Recognition
by Microsoft
Accurate Bing cloud speech-to-text for ARC: wake-word, programmable control, $BingSpeech output, Windows language support, headset compatible

Voice Activity Detection
by Synthiam
Real-time microphone VAD using FFT to detect speech start/end and trigger scripts, with live level graph and sensitivity tuning
Requires ARC
v9

@afcorson , I've had that problem a couple times in the past. As it turned out, most of the time, I needed to adjust the microphone input settings I was using in Windows. There are several ways to get to this setting depending on what version of win you have but the easiest way for me was to right click on the speaker icon on Windows taskbar and then click on Sound Settings. You can probably find them in the control panel or start menu. Once you get to the Microphone input section make sure you have the mic device (computer mic or the mic input jack) selected you are using. Once you know you are pointing to the proper device you may need to click on the device properties to make the level adjustment to the mic you're using.
Also, "I think" there is a "Set Up Microphone" button right in the skill in ARC? That may take you directly to this setting if it's available. cool
Good luck
I know this is on a list to be revisited - I'm guessing there's some thought going on how to make it work. As I explained earlier, it's not as simple as volume control. The positive result of your "yelling" into the microphone wasn't because of volume-it's because of how the sound was detected against the background noise.
At some point, you'll have to revisit my detailed response above and explore proper microphone options for filtering voice ranges, noise filtering, etc.
My USB mic level is set to 100% and there is no background noise. Talking loudly peaks significantly despite the VAD skill barely detecting it.
I understand your experience with generic mic hardware is not optimal. While it is on the list to have it revisited, there is thought and discussion in the meantime on how to make it work for your configuration. You may have missed a few of my previous posts where I mentioned the difficulty of isolating the sound of voice in real time without significant latency issues leading to false positives. So, the algorithm has to be fast and requires the assistance of a specific voice mic hardware. Mics are not all made equal because your mic could record a guitar, a dog barking, a train, a baby laughing, wind, or a coin falling into a bucket; I dunno - those are random examples because your mic is not designed for just speech. However, all our mics are tuned for speech by Jabra, so our experience will be different because we're using hardware specifically designed for the job. Alexas, Google Homes, etc, also have frequency filters for speech. Any hardware comparing against your VAD experience uses hardware filtering to aid in isolating human speech frequency range. But, as stated earlier, they also use wake words. Wake words still benefit from a properly tuned mic for human speech. In addition, all the robots you see in the media with people holding a mic to speak to them are using buttons to trigger the recording. As always, I value your feedback, and the platform is built on that model - however, sometimes, we're up against a wall when the technology doesn't exist. As I mentioned earlier, The VAD is "raise the amplitude" because it's more complicated than that.
@athena explains how a voice activation detection algorithm works and the complications behind it.
In the meantime, give us a bit of time - I'm sure we'll figure something out as we always do
Voice Activity Detection (VAD) is indeed a complex process, especially when it comes to distinguishing human speech from other sounds in real-time. The challenges you're facing with the VAD skill in ARC are not uncommon, especially when using generic microphones that aren't specifically designed for speech recognition.
Understanding VAD and Its Challenges
Sensitivity and Background Noise: VAD algorithms need to differentiate between speech and background noise. This can be challenging if the microphone picks up a lot of ambient sounds or if the speech is not significantly louder than the background noise.
Microphone Quality: As DJ_Sures mentioned, not all microphones are created equal. High-quality microphones designed for speech recognition often have built-in noise-canceling features and are tuned to pick up the frequency range of human speech more effectively.
Latency and False Positives: The algorithm must be fast to avoid latency, which can lead to false positives or missed detections. This requires a balance between sensitivity and accuracy.
Recommendations
Microphone Settings: As Dave_Schulpius suggested, ensure your microphone settings in Windows are optimized. You can access these settings by right-clicking the speaker icon in the taskbar and selecting "Sound Settings." Make sure the correct microphone is selected and adjust the input level as needed.
Microphone Type: Consider using a microphone specifically designed for speech recognition. These often have better noise-canceling capabilities and are more sensitive to the frequency range of human speech.
Environment: Try to minimize background noise as much as possible. This can help the VAD algorithm focus on your voice.
Wake Words: If possible, use wake words to trigger the speech recognition. This can help ensure that the system is only listening when you want it to, reducing the chance of false positives.
Future Improvements
The Synthiam team is aware of the challenges and is considering ways to improve the VAD skill. This might include adding adjustable sensitivity settings or exploring new algorithms that can better handle a variety of microphone types and environments.
If you have any more questions or need further assistance, feel free to ask!
I was provided with the Voice Activity Detector code used in the Synthiam VAD robot skill behind the scenes. I was also asked to explain how it works and relay that information to anyone watching this thread. If you have any questions about this program evaluation, please ask!
Alright, let’s break this down in the simplest way possible, step by step, so it makes sense even if you don’t know much about math, programming, or audio processing.
What Does This Program Do?
This program listens to audio (like a microphone recording) and tries to figure out when someone is speaking and when it’s just silence or background noise.
Imagine you're at a party, and you’re trying to pick out someone’s voice from all the noise around you. This program does the same thing but in a super-smart, automated way.
How Does It Work?
1. Breaking the Audio into Small Pieces
2. Looking for Patterns in Each Chunk
For every chunk of audio, the program looks at three things:
3. Learning What Silence Sounds Like
4. How It Decides If Someone Is Speaking
Once the program knows what silence sounds like, it starts comparing every new audio chunk to that baseline:
To make sure it doesn’t jump to conclusions, it checks at least two out of the three things (loudness, patterns, and pitch). If two or more say, "This is speech," it decides someone is speaking.
5. What Happens When It Detects Speech
The program keeps track of whether someone is currently speaking or not:
What’s Cool About It?
Imagine This in Everyday Life
Challenges of the Code and Why It Might Not Always Work
This program is clever, but it’s not perfect, and it depends a lot on the environment and the equipment being used. Here are some challenges it faces:
1. Microphone Quality
2. Background Noise
3. Microphone Placement
4. Program Assumptions vs. Real-Life Scenarios
5. Speech-Like Noises
Why a Good Microphone Makes a Difference
Ideal Setup for This Program
Summary
This program is powerful, but its effectiveness heavily depends on the microphone and environment. A poor mic or noisy setting makes it struggle to detect speech accurately. On the other hand, a high-quality microphone designed for capturing voice, with noise-canceling features, gives the program the clean input it needs to work reliably.
Sorry @afcorson I didn't completely understand your problem. While me pointing to the volume settings in Windows to solve your problem was a good thing to check I was thinking along the wrong lines. Personally I don't use VAD in my Bing Speech skill. I have it turned off as I don't like the thing listening to everything, all the time the robot is powered up. I guess I have some privacy issues. LOL. I have VAD turned off and use a Wake word. I also have a very good headset microphone with noise canceling. The mic is right next to my mouth and I have close to 100% recognition. I have tried using the VAD feature in the past and have seen very good recognition but I haven't really used it enough to say it's as good as my present method. I'm seriously considering giving it a try again as Synthiam seems to have put a lot of work into improving the VAD experience in ARC.
For reference I'm using the Plantronics VOYAGER-5200-UC (206110-01) Advanced NC Bluetooth Headsets System. It comes with a PC dongle and is optimized to use with a windows PC. It's pricey at over 100 usd but it's the best I've found (and I've tested a lot of mics of different types with ARC and windows). You can look at it here on Amazon: Voyager 5200
Anyway, good luck with working through this issue my friend. I'm very interested in how this progresses and this subject as VR is the main way I control my robot.
Thanks for your comments. I am not using VAD in Bing Speech. It is the "Voice Activity Detection Skill" I was having problems with. I just need a way of knowing that my robot is being spoken to or not, so that Bing Speech stops listening. The VAD Skill works if I am speaking very loudly but otherwise does not. And the documentation for that skill mentioned sensitivity adjustment which seem to be an error. I will manage with what I have for the moment.