
Mickey666Maus
Germany
Asked
— Edited

Tensor Flow Is Googles Open Source Machine Learning Api
Hey, I am not a Japanese cucumber farmer...only a German robot enthusiast, but I though maybe some of you might find this interesting!

Great software! Did you see this video?
https://youtu.be/_zZe27JYi8Y
Hey, I just realized they are building custom classifiers already here in the forum...I am in Japan at the moment, but I will dig in deeper once I am back!
YOLO is also very interesting...
Yes, YOLO is amazing. I'm attempting to get it to work on my PC.
YOLO, crazy amazing.
Some Yolo results:

Res: 320x240 (EZ Camera)
Res:4032x3024 (Iphone)
Res:4032x3024 (Iphone)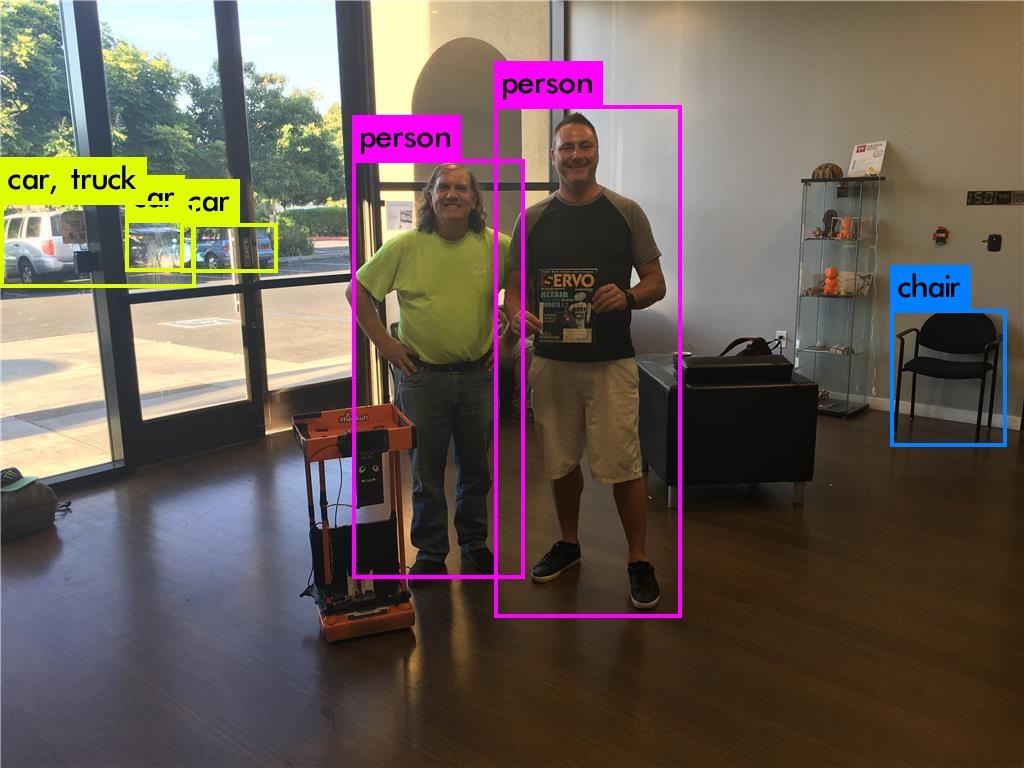
Res:1024x768
Res:1024x362all the detections used the same YOLO model (236 MB COCO Yolo v3) i believe the source for image and categories: https://cocodataset.org
Awsome!
Some Tensorflow results:
I presume the models have different training parameters.
Detection success depends on trained model.
So far you have:
Custom Classifier Training (Watson API), you upload images positive and/or negative images, Watson runs the black magic, and later you call Watson API to check for one or more custom classifiers. So far the API does not provide object location.
Watson Machine Learning / Azure Machine Learning: A more advanced solution, you train the models in the cloud, and the deployment is in cloud, the model can't be downloaded and used offline. I believe this solution requires more expertise, more data (images) and provides more details e.g. object locations. Can be used as building block for an application, you train the models you deploy to a watson application server and then you can develop a web API to be interfaced by third party clients.
Tensorflow / Caffe
3.1) Training you build/setup a machine to train your model, you will need a lot (i mean a lot) of images, and you will need special hardware: CUDA Video Board. IF you have plans to train images you will need something like a GTX 1080 TI https://www.amazon.com/EVGA-Optimized-Interlaced-Graphics-11G-P4-6393-KR/dp/B06Y11DFZ3 starting at $1000, plus you will need a decent ICore 7 CPU, plus refrigeration, memory and SSD everything easily available if you have a Credit Card.
Or you look for an online solution (Virtual Machine with NVidia board) available at amazon: https://aws.amazon.com/about-aws/whats-new/2016/09/introducing-amazon-ec2-p2-instances-the-largest-gpu-powered-virtual-machine-in-the-cloud/
you pay time used to train the model it can be a few hours or days.
If you use the Tensorflow or Caffe solutions you can download the model and use it offline.
3.2) Using the model You don't need a GPU to use a trained model, depending on the model complexity you will need CPU/Memory
There are some interesting solutions to accelerate the recognition (not the training):
3.2) Movidius chip My Google Tango Tablet has the chip, it was a great thing when was released, unfortunately Google killed the Tango Project. So now is part of the History Channel.
Intel bought the Movidius company, and they released the Intel Movidius Stick https://developer.movidius.com ($80). So far only Linux is supported.The information is limited, but it's a great addition for a Raspberry PI 3 and can boost the detection time. Supports both Tensorflow and Caffe models.
Google released the AIY vision project https://aiyprojects.withgoogle.com/vision and create a PCB with movidius chip as a backpack add-on to Raspberry PI Zero $5 (ArmV6) or Raspberry PI 2/3 (ArmV7). I got one ($45) before they went out of stock. It's a nice add-on for a Raspberry PI Zero low cost board, google PCB uses SPI connection, they also connect directly to the PI camera BUS to allow video recognition otherwise you need to capture frame after frame and send to the VPU chip.
Robotic Embedded Hardware: Nvidia Jetson TK1 (old history) basically the CPU power is similar to a Raspberry PI but they have a CUDA VPU, so it can make a difference when you use vision algorithms compiled for CUDA. Nvidia Jetson TX1 more powerful plus $$ Both boards support Linux and ROS, once again if you are using vision / machine learning (recognition) these boards can make the difference.
So to summarize Machine Learning is here, it's easy to play with the existent models, can be a frustration if you try to detect objects not previously available in the trained models.
Training is a different story, you will need to develop the expertise and have the right hardware (CUDA board GTX 1060 6GB, GTX 1070/1080) OR you stick with Watson and/or similar Azure, Google cloud apis.