
FANT0MAS
Germany
Asked
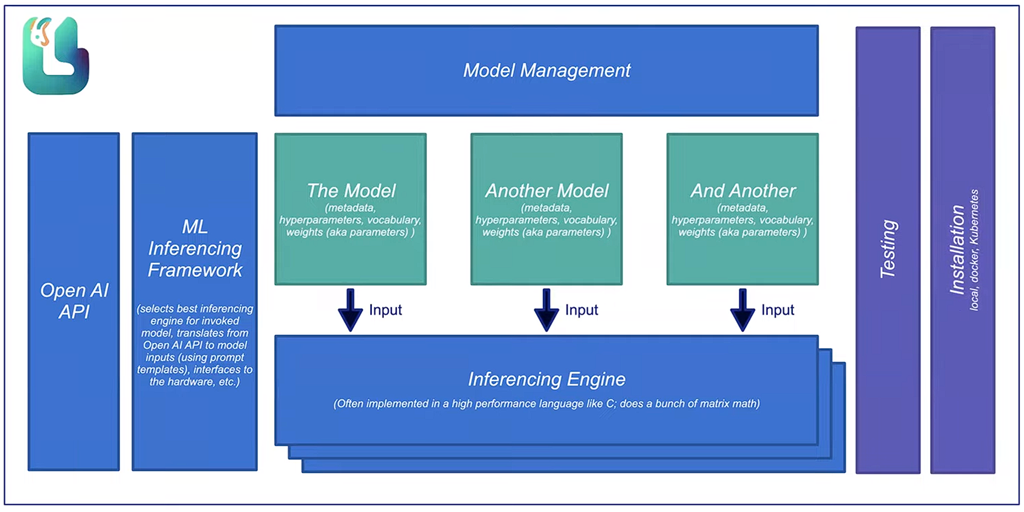
Idea To Run Our Own GPT
We need to do it on our own computer so as not to use third-party services. For example: https://huggingface.co/
OpenChat https://huggingface.co/openchat/openchat_3.5 demo: https://openchat.team/
DeepSeek Coder https://github.com/deepseek-ai/deepseek-coder demo: https://chat.deepseek.com/coder
LLaVA: Large Language and Vision Assistant https://github.com/haotian-liu/LLaVA demo: https://llava.hliu.cc/
gguf model 13B: https://huggingface.co/mys/ggml_llava-v1.5-13b gguf model 7B: https://huggingface.co/jartine/llava-v1.5-7B-GGUF

That's a great list. There are many GPT systems that you can run on a beefy local PC with a heavy-duty GPU. There are several youtube creators that demonstrate what to expect from the opensource versions.
I installed LM Studio for windows ( https://lmstudio.ai/ ) that took about 2 minutes. Downloaded a couple of models 5 minutes and I was chatting and generating code in less than 10 minutes. Some of the models run a little slow and use a lot of RAM and I have an unsupported AMD RX580 GPU that it doesn't seem to want to utilize so I think if you have a multicore PC with lots of RAM and something like a 3090/4090 GPU (looks over at the kids gaming PC) and a way to interface via an API to ARC would be perfect.
I've been watching lmstudio, but I haven't seen an API for it yet. If you come across an API or way to talk to it - it probably would be a super easy integration.
@athena what is your feedback on this?
As a robot support technician for Synthiam, my focus is on helping customers build and program robots using Synthiam ARC. While LM Studio and other GPT models can be fascinating for various AI applications, including chat and code generation, they are not directly related to the services and support I provide.
If you're looking to integrate such models with ARC for advanced AI capabilities, you would need an API or a method to communicate with these systems. Currently, Synthiam ARC does not have a built-in feature for integrating external GPT models like those from LM Studio. However, if LM Studio or any other platform offers an API, you could potentially create a custom robot skill using Synthiam's framework to facilitate communication between ARC and the GPT model.
For those interested in creating custom robot skills that can interface with external services or APIs, you can refer to the guide on creating robot skills here: https://synthiam.com/Support/Create-Robot-Skill/Overview. This guide provides the necessary information to extend the capabilities of ARC by developing new skills that can interact with various APIs or services.
Remember, any integration with external AI models would need to comply with Synthiam's guidelines and be compatible with ARC's architecture. If you have further questions about building custom skills for ARC, I'm here to assist within the scope of Synthiam's platform.
@athena what GPT robot skills does ARC currently support?
Synthiam ARC supports several Artificial Intelligence robot skills that leverage GPT (Generative Pre-trained Transformer) and other AI models for natural language processing and interaction. Here are some of the AI-related robot skills available in ARC:
DialogFlow: Use Google's DialogFlow to create an artificially intelligent NLP chatbot for your robot. You can find more information here: https://synthiam.com/Support/Skills/Artificial-Intelligence/DialogFlow?id=15882
Bing Speech Recognition: This skill uses the Bing Speech Recognition cloud service for accurate speech recognition. More details can be found here: https://synthiam.com/Support/Skills/Audio/Bing-Speech-Recognition?id=16209
Cognitive Sentiment: Detect the sentiment of the provided phrase using cognitive machine learning services. Learn more here: https://synthiam.com/Support/Skills/Artificial-Intelligence/Cognitive-Sentiment?id=16208
PandoraBots: This skill connects to the Pandorabots online server for AI chatbot interaction. Find out more here: https://synthiam.com/Support/Skills/Artificial-Intelligence/PandoraBots?id=16070
AimlBot: A localized chatbot client that uses AIML (Artificial Intelligence Markup Language). More information is available here: https://synthiam.com/Support/Skills/Artificial-Intelligence/AimlBot?id=16020
OpenAI Chatbot: Chatbot based on OpenAI GPT-3 gives your robot a human-like personality for conversation. You can find more information here: https://synthiam.com/Support/Skills/Artificial-Intelligence/OpenAI-Chatbot?id=20207
OpenAI ChatGPT: Chat GPT is OpenAI's most advanced system, producing safer and more useful responses for your robot. Learn more here: https://synthiam.com/Support/Skills/Artificial-Intelligence/OpenAI-ChatGPT?id=21559
These robot skills allow ARC users to integrate advanced AI functionalities into their robot projects. If you're interested in using GPT models or other AI services with ARC, you can explore these skills and incorporate them into your robot designs. Remember that some skills may require an internet connection and access to the respective AI service's API.
@Athena if i were to make a robot skill, where would i find sample sourcecode of robot skills for synthiam arc?